문제링크
https://leetcode.com/problems/pacific-atlantic-water-flow/description/
Pacific Atlantic Water Flow - LeetCode
Can you solve this real interview question? Pacific Atlantic Water Flow - There is an m x n rectangular island that borders both the Pacific Ocean and Atlantic Ocean. The Pacific Ocean touches the island's left and top edges, and the Atlantic Ocean touches
leetcode.com
문제설명
There is an m x n rectangular island that borders both the Pacific Ocean and Atlantic Ocean. The Pacific Ocean touches the island's left and top edges, and the Atlantic Ocean touches the island's right and bottom edges.
The island is partitioned into a grid of square cells. You are given an m x n integer matrix heights where heights[r][c] represents the height above sea level of the cell at coordinate (r, c).
The island receives a lot of rain, and the rain water can flow to neighboring cells directly north, south, east, and west if the neighboring cell's height is less than or equal to the current cell's height. Water can flow from any cell adjacent to an ocean into the ocean.
Return a 2D list of grid coordinates result where result[i] = [ri, ci] denotes that rain water can flow from cell (ri, ci) to both the Pacific and Atlantic oceans.
Example 1:
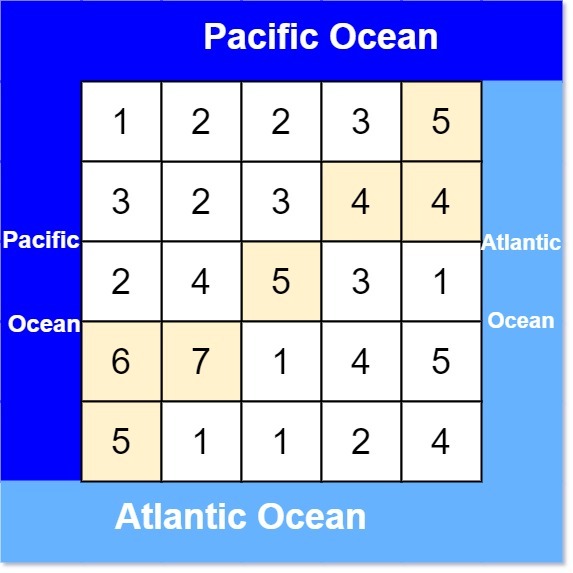
Input: heights = [[1,2,2,3,5],[3,2,3,4,4],[2,4,5,3,1],[6,7,1,4,5],[5,1,1,2,4]]
Output: [[0,4],[1,3],[1,4],[2,2],[3,0],[3,1],[4,0]]
Explanation: The following cells can flow to the Pacific and Atlantic oceans, as shown below:
[0,4]: [0,4] -> Pacific Ocean
[0,4] -> Atlantic Ocean
[1,3]: [1,3] -> [0,3] -> Pacific Ocean
[1,3] -> [1,4] -> Atlantic Ocean
[1,4]: [1,4] -> [1,3] -> [0,3] -> Pacific Ocean
[1,4] -> Atlantic Ocean
[2,2]: [2,2] -> [1,2] -> [0,2] -> Pacific Ocean
[2,2] -> [2,3] -> [2,4] -> Atlantic Ocean
[3,0]: [3,0] -> Pacific Ocean
[3,0] -> [4,0] -> Atlantic Ocean
[3,1]: [3,1] -> [3,0] -> Pacific Ocean
[3,1] -> [4,1] -> Atlantic Ocean
[4,0]: [4,0] -> Pacific Ocean
[4,0] -> Atlantic Ocean
Note that there are other possible paths for these cells to flow to the Pacific and Atlantic oceans.
Example 2:
Input: heights = [[1]]
Output: [[0,0]]
Explanation: The water can flow from the only cell to the Pacific and Atlantic oceans.
Constraints:
- m == heights.length
- n == heights[r].length
- 1 <= m, n <= 200
- 0 <= heights[r][c] <= 105
문제풀이
처음엔 여타 그래프 탐색 문제를 풀듯이 인접행렬로 BFS 돌려서 조건에 맞게 좌표를 산출하면 되겠거니 하는 안일한 생각이었다.
하지만 이중for문으로 모든 좌표에서 BFS를 시행하는 것이 과연 맞는 전략일까 라는 의문이 들었고,
또 우측, 하측에 있는 Atlantic 바다와 좌, 상측에 있는 Pacific 바다로
모두 흐르는 좌표를 체킹하는 접근법이 떠오르지 않아서 레퍼런스를 참고했다.
그 결과 다시 세운 핵심전략은,
1. 시작좌표를 각 바다와 인접한 좌표들로만 배열을 구성한다. (Pacific, Atlantic 나눠서)
2. 파이썬의 set() 을 사용
- Pacific으로 흐를 수 있는 좌표들의 set(), Atlantic으로 흐를 수 있는 좌표들의 set() 을 따로 구하기.
=> 따로 BFS시행해야겠지
- BFS 내에서도 visited라는 set()을 활용. 바다와 인접한 스타트 좌표들을 전부삽입.
그리고 BFS를 통해 조건에 부합하여 큐에 삽입될때마다(방문할 때마다) 삽입
3. 구한 집합들의 교집합을 구하면 된다. (set문법 활용)
리트코드는 다른 알고리즘 플랫폼들과 달리 이렇게 본인이 푼 솔루션의 시간복잡도, 공간복잡도 랭킹(?)도 알 수 있다.
코드
from collections import deque
class Solution:
def pacificAtlantic(self, heights: List[List[int]]) -> List[List[int]]:
d = [(0, 1), (0, -1), (1, 0), (-1, 0)] #동, 서 남, 북
m = len(heights)
n = len(heights[0])
pacific = set() # pacific 바다로 흐를 수 있는 좌표들 집합
atlantic = set() # atlantic 으로 흐를 수 있는 좌표들 집합
def bfs(starts):
queue = deque(starts)
visited = set(starts)
while queue:
curX, curY = queue.popleft()
for dx, dy in d:
nx = curX + dx
ny = curY + dy
# 육지내에 속하고, 방문하지 않았고, 이전 셀의 높이보다 높아야함.
if 0 <= nx < m and 0 <= ny < n and (nx, ny) not in visited and heights[nx][ny] >= heights[curX][curY]:
queue.append((nx, ny))
visited.add((nx, ny))
return visited
# 각 바다와 인접한부분의 좌표를 각 바다의 스타트 배열로 만든다.
pStart = [(0, i) for i in range(n)] + [(i, 0) for i in range(1, m)]
aStart = [(m-1, i) for i in range(n)] + [(i, n-1) for i in range(m-1)]
pacific = bfs(pStart)
atlantic = bfs(aStart)
return list(pacific & atlantic) # 교집합 구해서 리스트 변환.
# 핵심 아이디어: BFS
# for문 돌려서 각지점에서 BFS 전부 시행??
# 아틀란틱 => 우, 하 / 패시픽 -> 좌, 상 인데 체크조건을 어떻게 잡아야할까??'알고리즘 > 리트코드' 카테고리의 다른 글
| [LeetCode 49] Group Anagrams (with Python / 문자열) (0) | 2023.12.19 |
|---|---|
| [LeetCode 300] Longest Increasing Subsequence (with Python / DP) (0) | 2023.12.19 |
| [LeetCode] twoSum (with Python) (0) | 2023.08.27 |

